
I’ve been playing around with Google’s programming language known simply as Go lately, and have learned quite a bit about concurrency, parallelism, and writing code to effectively use multiple CPU cores in the process.
An Overview of Go

If you are used to programming at the systems level, Go is effectively a replacement for C, but also has higher level functionality.
- It is strongly typed
- It can be compiled
- It has its own unit testing framwork
- It has its own benchmarking framework
- Doesn’t support classes, but supports structures and attaching functions to variables instantiated from those structures
- Doesn’t expose threads, but instead uses a construct called “channels” for communication between different parts of a Go program. More on channels shortly.
Your First Go Program
First, let’s start with this Go code, which I will walk you through:
c := make(chan string, config.Buffer_size)
num_cores := 1
for i:=0; i<num_cores; i++ {
go func(c chan string) {
for {
<-c
}
}(c)
}
message := "x"
for i:=0; i<10000000; i++ {
c <- message
}
What this piece of code does is it creates a channel–a construct similar to named pipes in UNIX or SQS queues in Amazon Web Services. One part of code can write to a channel while another piece of the code can read from the same channel and performed a NOOP. It also defines a function inline and precedes it with the keyword “go”. That function is then launched in the background as a “goroutine”. Goroutines can be thought of as “lightweight threads”. Thousands of them can be spawned over the lifetime of a Go program with little impact on performance. If the “num_cores” variable is tweaked in the above code, the run time of the program should decrease as there will be multiple cores reading messages off of the channel. Finally, the code writes the string “x” into the channel 10 million times. Assuming the goroutine is running, the loop to populate the channel should execute on one core while the goroutines which read from the channel should execute on the other cores.
So let’s try that now:
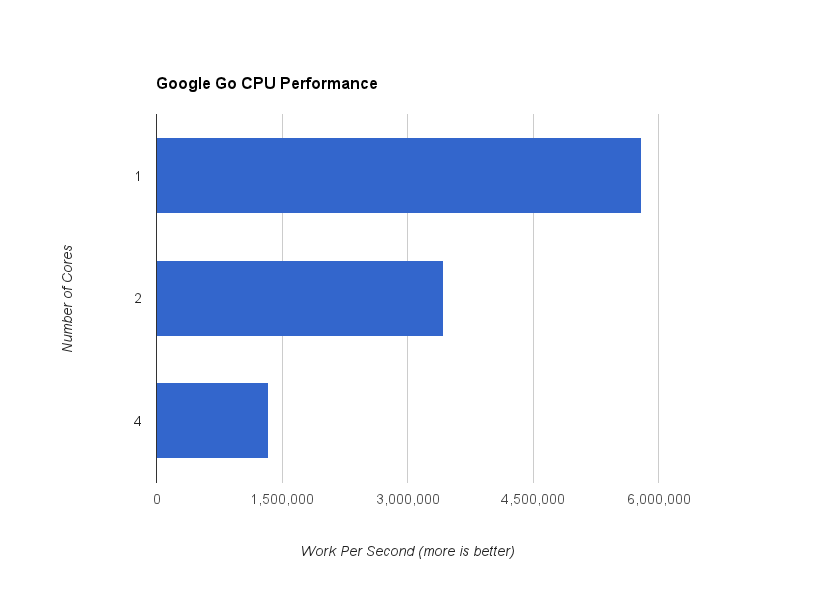
Wait, what? What just happened? Multiple cores is supposed to make things faster, right?
Working more != working more effectively
The problem that we ran into here is that there is overhead involved when a message is created on one core and read on another. In the first instance, core #1 ran at 100% effectiveness. When I ran this script with 4 cores, the effectiveness per core was more like 20%. I’m not a hardware engineer so I can only make a few guesses here, but I wouldn’t be surprised if there was an issue with L1 cache invalidation or perhaps saturation of the interconnections between individual cores. Either way, we’d like to avoid that.
Does this actually happen in the real world?
Potentially, yes. I first ran into this issue when I getting my feet wet with Go and wrote a Monte Carlo simulation. I was generating many millions of random numbers and couldn’t figure out why performance got worse with more CPUs added. Another real world possibility is a persistent process which performs simple calculations such as keeping track of hits to a specific web service.
Message less, do more
While decoupling parts of data flows is generally a good idea, it can come back to bite you, as we saw here. One way to keep this particular issue from happening would be to ensure that each message successfully read results in more work being done. Going back to the Monte Carlo example I was working on, one solution would be to pass an integer into that channel, telling just how many random numbers you would like created. Then each Goroutine has more work to perform, and will spend more time doing that work and less time processing messages.
I modified the above code to place a for() loop in the Goroutine that would simply count up a list of integers as “work”. I could then modify how high to count so that more time was spent processing each message. This is what the code looks like now:
c := make(chan string, config.Buffer_size)
num_cores := 1
for i:=0; i<num_cores; i++ {
go func(c chan string) {
for {
for i:=0; i<num_goroutine_work; i++ {
<-c
}
}
}(c)
}
message := "x"
for i:=0; i<10000000; i++ {
c <- message
}
Now the goroutine does some “work” based on what the variable “num_goroutine_work” is set to.
Here’s how that turned out:

With 32 units of work per message received, we can see that performance on 4 cores is much better than before, but not nearly as good as performance on 1 core. Let’s raise the amount of work per message received even higher:

Ah, much better! The tide starts to turn at 512 units of work per message, and peaks at 32K units of work per message. That’s the sort of behavior I expected to see in Google Go. Good times.
My testing platform
For those who would like to reproduce these tests, I ran Go version 1.0.3 on a 3.4 Ghz Intel Core i7 processor under Mac OS/X. The code I used can be found over on GitHub. 🙂
I hope you enjoyed learning something about Google Go which took me much frustration and trial and error on my part to learn. As always, if there are any questions, comments, or gripes, please let me know in the comments!