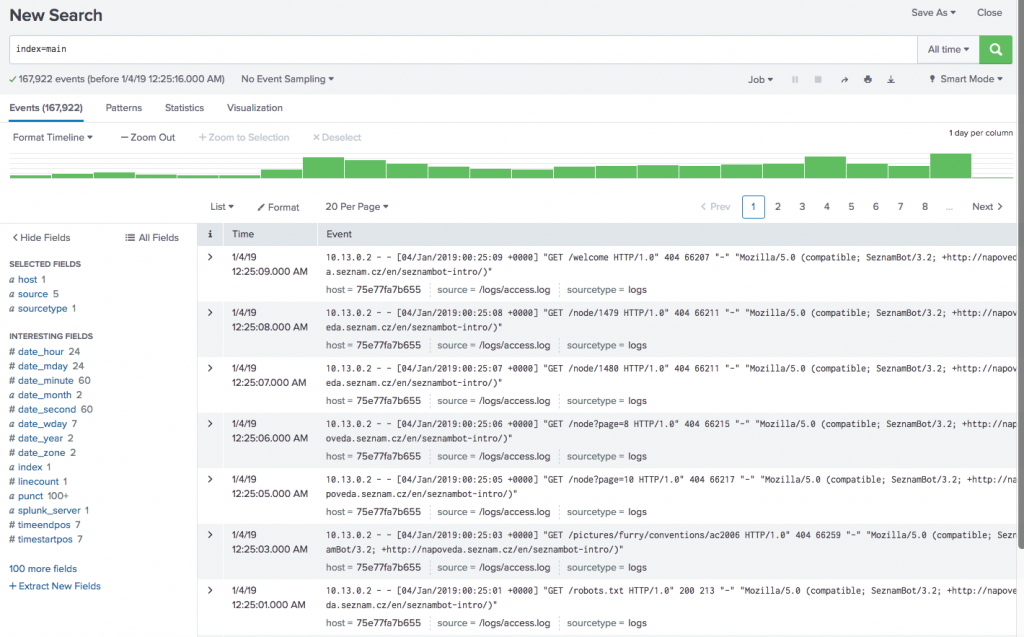
If you are storing files in Amazon S3, you absolutely positively should enable AWS S3 Access Logging. This will cause every single access in a bucket to be written to a logfile in another S3 bucket, and is super useful for tracking down bucket usage, especially if you have any publicly hosted content in your buckets.
But there’s a problem–AWS goes absolutely bonkers when it comes to writing logs in S3. Multiple files will be written per minute, each with as few as one event in them. It comes out looking like this:
2019-09-14 13:26:38 835 s3/www.pa-furry.org/2019-09-14-17-26-37-5B75705EA0D67AF7
2019-09-14 13:26:46 333 s3/www.pa-furry.org/2019-09-14-17-26-45-C8553CA61B663D7A
2019-09-14 13:26:55 333 s3/www.pa-furry.org/2019-09-14-17-26-54-F613777CE621F257
2019-09-14 13:26:56 333 s3/www.pa-furry.org/2019-09-14-17-26-55-99D355F57F3FABA9
At that rate, you will easily wind up with 10s of thousands of logfiles per day. Yikes.
Dealing With So Many Logfiles
Wouldn’t it be nice if there was a way to perform rollup on those files so they could be condensed into fewer bigger files?
Well, I wrote an app for that. Here’s how to get started: first step is that you’re going to need to clone that repo and install Serverless:
git clone git@github.com:dmuth/aws-s3-server-access-logging-rollup.git
npm install -g serverless
Serverless is an app which lets you deploy applications on AWS and other cloud providers without actually spinning up virtual servers. In our case, we’ll use Serverless to create a Lambda function which executes periodically and performs rollup of logfiles.
So once you have the code, here’s how to deploy it:
cp serverless.yml.exmaple serverless.xml
vim serverless.xml # Vim is Best Editor
serverless deploy # Deploy the app. This will take some time.