
I’m a big fan of Amazon S3 for storage, and I like it so much that I use Odrive to sync folders from my hard drive into S3 use S3 to store copies of all of my files from Dropbox as a form of backup. I only have about 20 GB of data that I truly care about, so that should be less than a dollar per month for hosting, right? Well…

Close to 250 GB billed for last month. How did that happen?
I have versioning turned on on all of my buckets, so as to prevent against accidental deletion. Could that have caused all the disk usage? I have thousands of files, so it’s hard to say.
I needed a way to go through all of my S3 files and print up stats on them. I originally planned to do this all using Boto 3, and since I wanted all versions of files, it meant I would have have to use S3.Paginator.ListObjectsV2 to get that data. Unfortunately, I found what appears to be a bug: the NextTokenvalue was not being populated, which means I couldn’t fetch more than a single batch of file data.
So much for Boto.
I did more investigating and AWS CLI actually provides low-level access to the S3. All you have to do is create a set of AWS credentials with read-only access to S3:
And then run aws s3api list-object-versions — bucket BUCKET_NAME to verify that you can pull up data on a bucket. I then built an app (available on GitHub) to process the contents for each bucket, and started digging through my buckets.
First stop, this bucket:
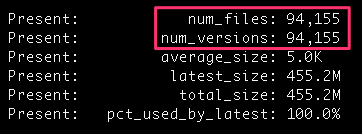
94,000 files? What’s going on there? A quick dig through that bucket revealed that I had CloudTrail enabled on that bucket, and the logs were being written in the same bucket. I redirected those logs to my logging bucket, deleted the unwanted files, and things looked a lot better:
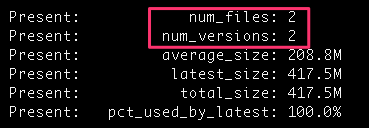
But even though that was a lot of files, it was nowhere near 200 GB, or even 1 GB. I continued to dig and came across this bucket:
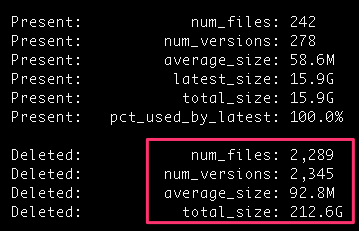
Well that’s quite a bit of space used, and by deleted files — it seems their old versions were kept around. That bucket is used to hold daily backups from one of my projects, and it turns out that my Lifecycle rules on that bucket were set up to keep my files for over a year:
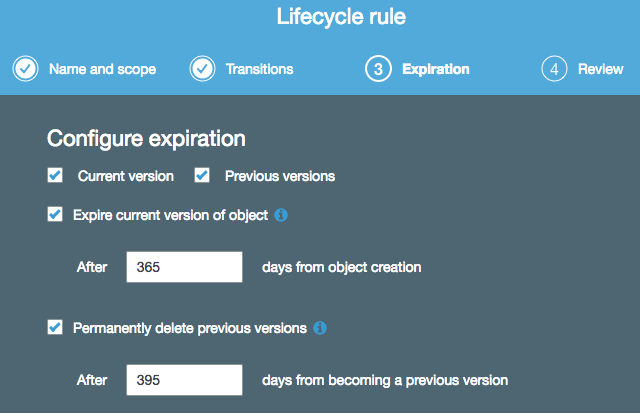
A quick tweak of that to just 60 days dropped my usage considerably, and now my usage is somewhere around 37 GB in that bucket:
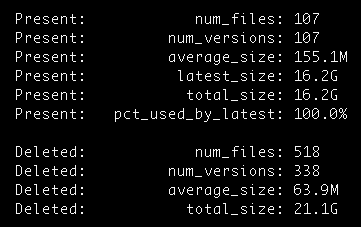
Lessons Learned
Versioning and Lifecycle Rules are powerful features for AWS S3. They can protect against accidental deletions and prune old files and old versions. But if you’re not paying attention, the data used by old versions can really add up and inflate your AWS bill.
My tool to determine S3 usage can be found on GitHub: https://github.com/dmuth/s3-disk-usage
What Did You Think?
If you have any feedback on this post, feel free to drop me a line or leave a comment below.