In a previous post, I wrote about using Splunk to monitor network health. While useful for home and office use, there’s another valuable use for this app, and that’s when traveling.
In my case, over my Christmas vacation, I checked into a Mom and Pop hotel, or rather a motel! It was about 24 rooms all in a row, occupying a single floor. Since they were on a budget, their Internet offering consisted of what appeared to be 5 or 6 Linksys routers set up every few rooms. You’d simply connect to the closest access point and have Internet.
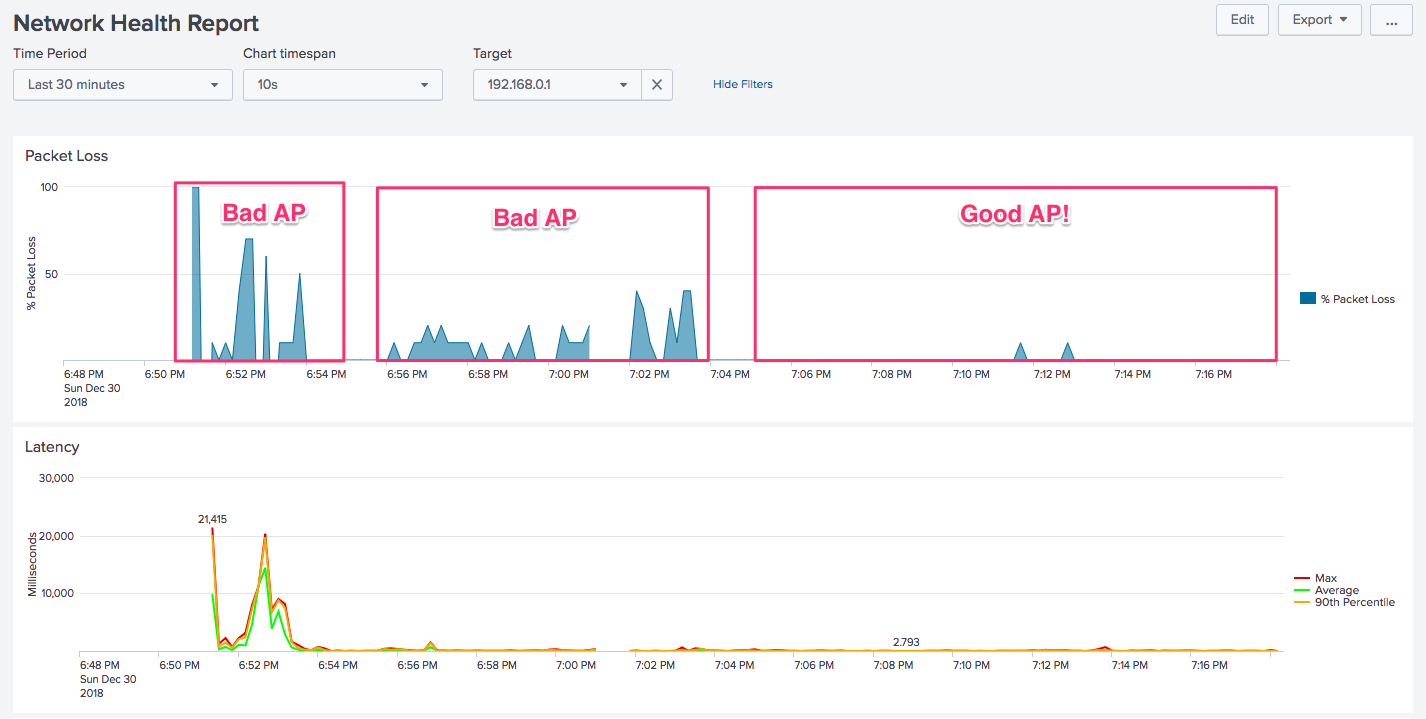
But there was a problem: determining which access point was closest to me! The signal strength indicator on my computer showed several of them were 3/3 bars so that wasn’t much help. I tried connecting to the first one, but had virtually no Internet connectivity.
That’s when I fired up Splunk:
SPLUNK_START_ARGS=--accept-license \
TARGETS=google.com,1.1.1.1,8.8.8.8,192.168.1.1 \
bash <(curl -s https://raw.githubusercontent.com/dmuth/splunk-network-health-check/master/go.sh)
Running that command will print up a confirmation screen so that you can back out and change any options (such as hosts to ping), and when you’re ready, just hit <ENTER> to start the container.
In the above example, I added in the TARGETS environment variable, and was sure to include 192.168.1.1, which was the IP for each router (they were all the same). Then I set Splunk “real-time mode” and periodically checked that tab as I was working. This is what I saw: